Sai Kumar Dwivedi

For a complete list of publications, visit my Google Scholar profile.
2025

InteractVLM: 3D Interaction Reasoning from 2D Foundational Models
Sai Kumar Dwivedi, Dimitrije Antić, Shashank Tripathi, Omid Taheri, Cordelia Schmid, Michael J. Black, Dimitrios Tzionas
CVPR, 2025
Won Human Contact Challenge at CVPR 2025
(see here)

PICO: Reconstructing 3D People In Contact with Objects
Alpár Cseke*, Shashank Tripathi*, Sai Kumar Dwivedi, Arjun Lakshmipathy, Agniv Chatterjee, Michael J. Black, Dimitrios Tzionas
CVPR, 2025
2024

TokenHMR: Advancing Human Mesh Recovery with a Tokenized Pose Representation
Sai Kumar Dwivedi*, Yu Sun*, Priyanka Patel, Yao Feng, Michael J. Black
CVPR, 2024
Integrated into Meshcapade's commercial solution
(see here)
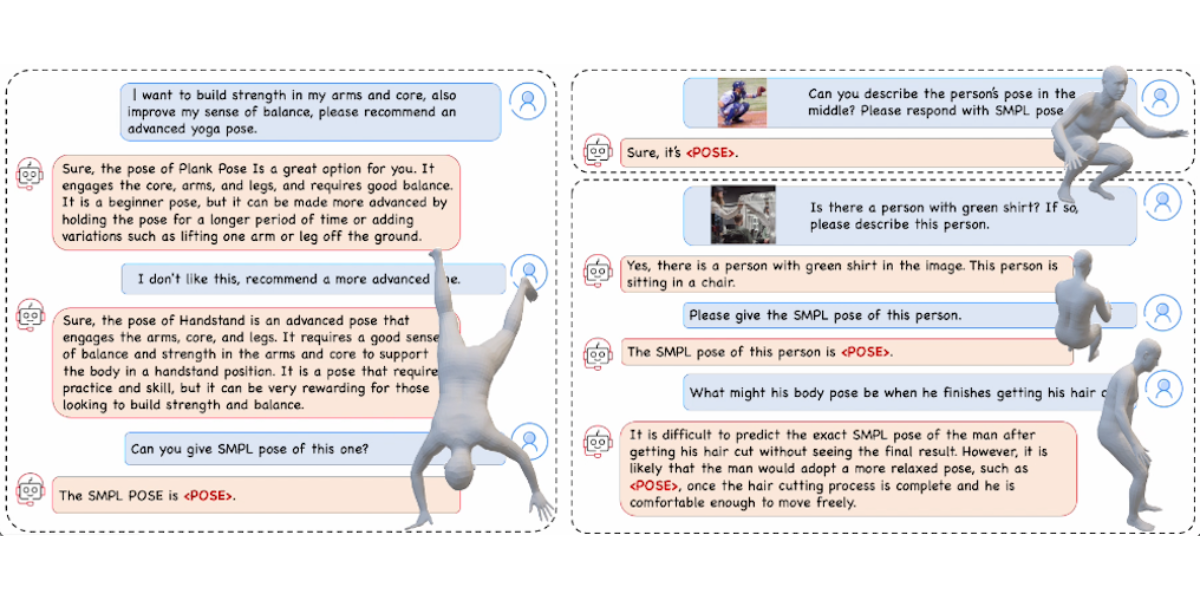
ChatPose: Chatting about 3D Human Pose
Yao Feng*, Jing Lin*, Sai Kumar Dwivedi, Yu Sun, Priyanka Patel, Michael J. Black
CVPR, 2024

POCO: 3D Pose and Shape Estimation using Confidence
Sai Kumar Dwivedi, Cordelia Schmid, Hongwei Yi, Michael J. Black, Dimitrios Tzionas
3DV, 2024 (Oral)
Featured in RSIP Vision Magazine (see here)
2023

Detecting Human-Object Contact in Images
Yixin Chen, Sai Kumar Dwivedi, Michael J. Black, Dimitrios Tzionas
CVPR, 2023
2021
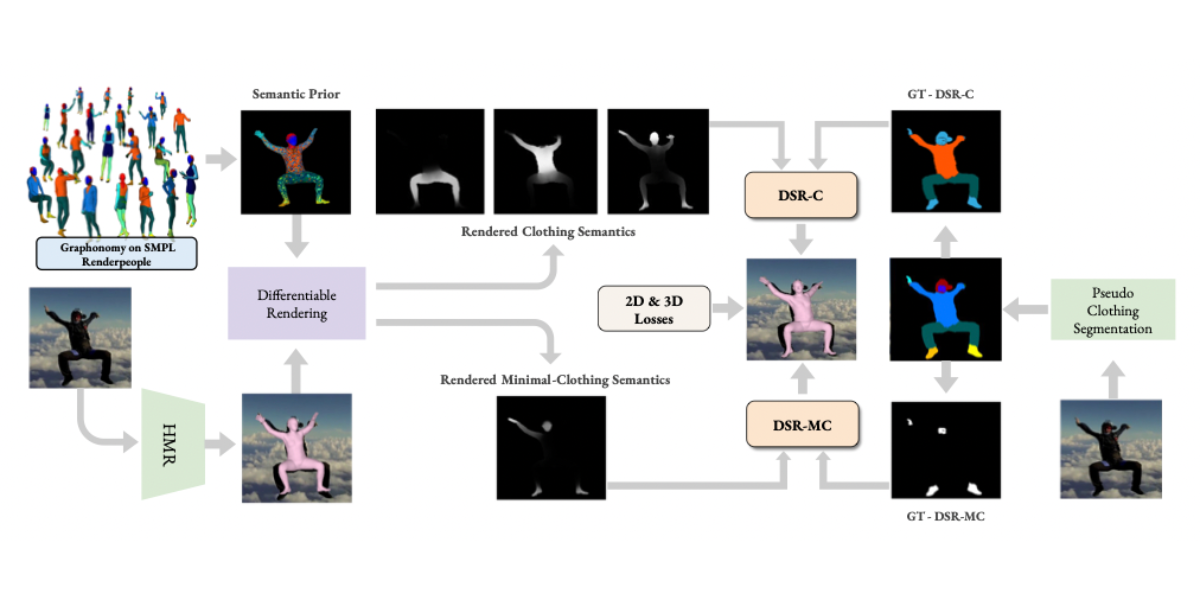
Learning to Regress Bodies from Images using Differentiable Semantic Rendering
Sai Kumar Dwivedi, Nikos Athanasiou, Muhammed Kocabas, Michael J. Black
ICCV, 2021
2019
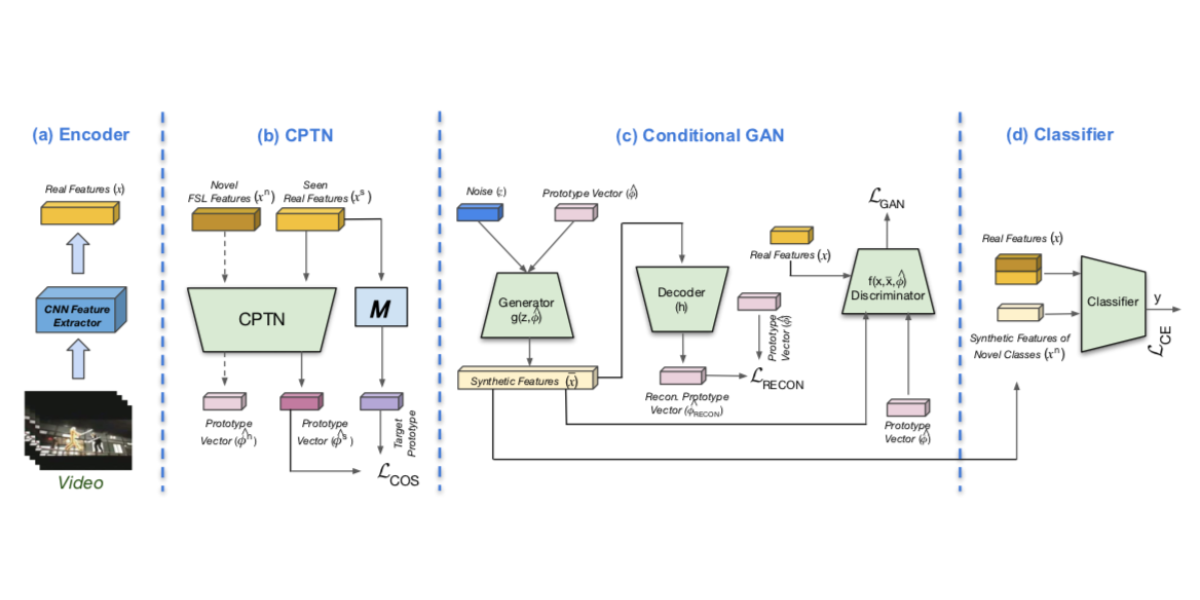
ProtoGAN: Towards Few Shot Learning for Action Recognition
Sai Kumar Dwivedi, Vikram Gupta, Rahul Mitra, Shuaib Ahmed, Arjun Jain
ICCV Workshops, 2019
Show Summary | arXiv | Paper | Data | ICCV Workshops 2019
ProtoGAN addresses the challenge of few-shot learning for action recognition by synthesizing additional examples for novel categories using class prototype vectors, improving generalization towards novel classes.
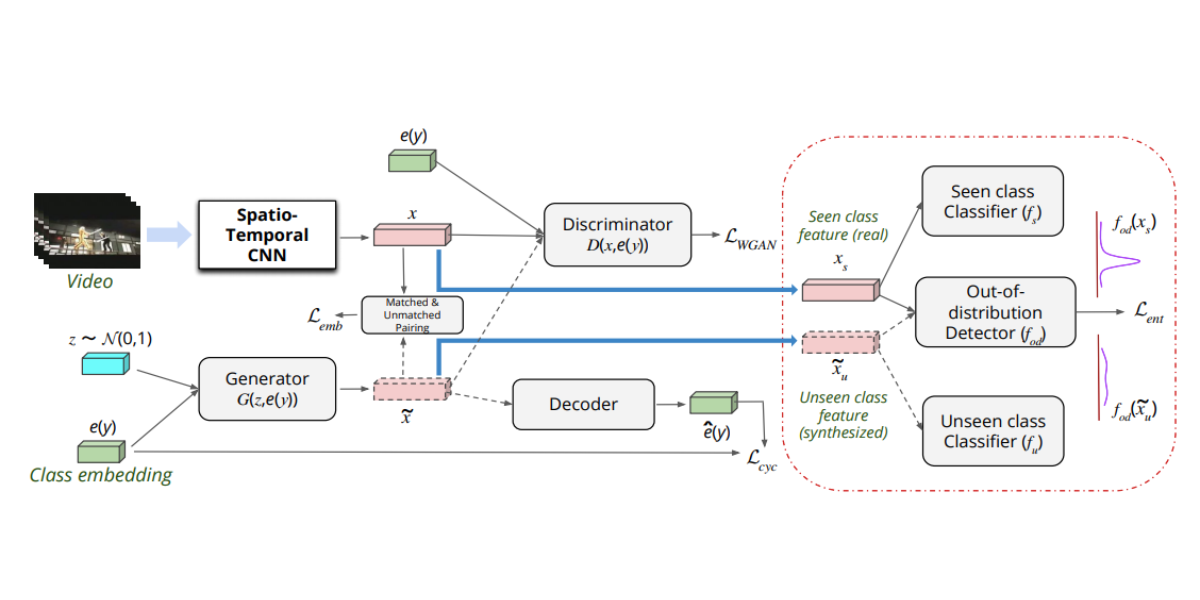
Out-Of-Distribution Detection for Generalized Zero-Shot Action Recognition
Devraj Mandal, Sanath Narayan, Sai Kumar Dwivedi, Vikram Gupta, Shuaib Ahmed, Fahad Shahbaz Khan, Ling Shao
CVPR, 2019
Show Summary | arXiv | Paper | Code | CVPR 2019
While addressing the challenges of generalized zero-shot action recognition, our novel framework incorporates an out-of-distribution detector to distinguish between seen and unseen action categories, achieving significant improvements over existing methods.
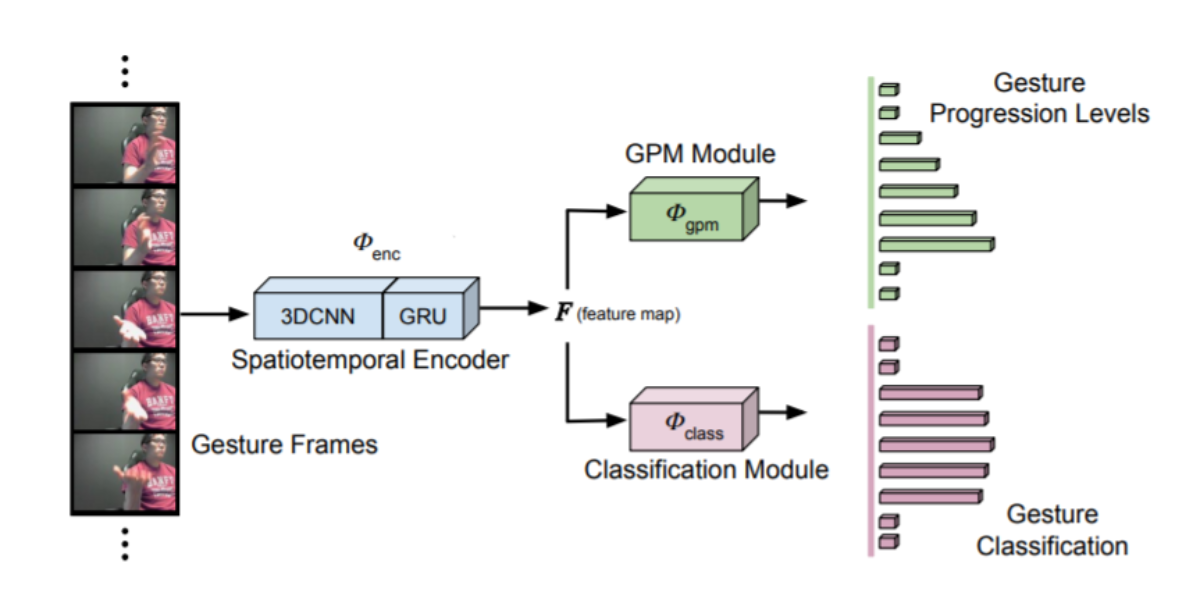
Progression Modelling for Online and Early Gesture Detection
Vikram Gupta, Sai Kumar Dwivedi, Rishabh Dabral, Arjun Jain
3DV, 2019 (Oral)
Show Summary | arXiv | Paper | Data | 3DV 2019
Our simple yet effective multi-task learning framework addresses the issue of online and early gesture detection by modelling the gesture progression along with frame level recognition.